Introduction to Apache Flink
published on Monday, December 01, 2014
Hadoop의 MapReduce 프레임워크를 통해서 데이터 처리를 해본 사람들은 알겠지만, 사실 MapReduce 프레임워크를 통해 데이터를 처리하는 것은 불편한 점이 한 둘이 아니다. 기본적으로 지원하는 연산이 Map과 Reduce 둘 만 제공되어 모든 알고리즘을 Map, Reduce의 반복을 통해 구현해야 하는 점[1], 병렬 최적화를 사실상 수동으로 수행해야해서 복잡한 알고리즘의 경우 최적화가 어려운 점, 중간 결과물도 HDFS에 저장해야해서 많은 I/O를 발생시키는 점[2] 등이 대표적이다. 특히 MapReduce 프레임워크가 HDFS랑 밀접하게 붙어 작동하는 것은 성능 저하에 꽤 큰 부분을 차지했는데 특히 반복 기반으로 작동되는 알고리즘들은 중간 결과물이 많아져 복잡한 처리를 하지 않으면 성능이 급격하게 떨어진다.
위와 같은 문제점 들을 해결하기 위해, MapReduce 프레임워크 위의 다른 프론트엔드[3]를 사용하거나 다른 패러다임의 데이터 처리 프레임워크[4]를 사용하는 추세가 이어지고 있다.
Apache Flink는 MapReduce 프레임워크를 쓰지 않는 독자적인 데이터 처리 프레임워크로 반복 기반의 알고리즘을 처리할 때 대폭적인 성능 향상을 보인다. 모든 데이터는 Read-Only 이며, 모든 연산은 새로운 데이터 셋을 계속해서 생성하는 형태로 수행된다. 함수형 프로그래밍의 특징을 그대로 계승하므로 병렬 최적화를 높은 수준으로 수행할 수 있다.
Flink의 데이터 단위는 DataSet 이며, DataSet을 연산할 수 있는 Operator가 존재한다. 프로그램은 DataSet에 다양한 Operator를 적용해 데이터를 처리하는 형태로 구성된다.
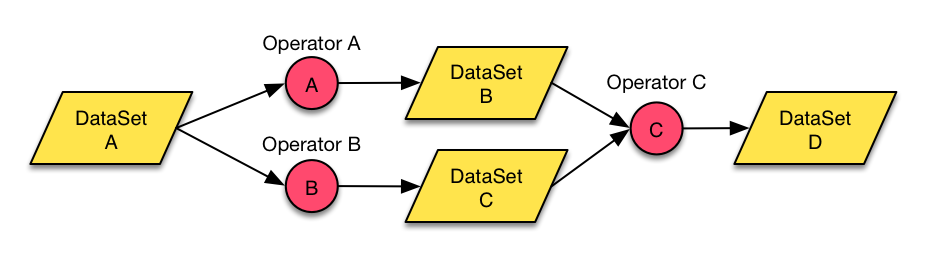
또한, Map, Reduce 이외에도 Join, CoGroup, Union, Iterate, Delta Iterate, Filter, FlatMap, GroupReduce, Project, Aggregate, Distinct, Accumulation 등 다양한 연산을 지원하여 MapReduce 프레임워크 보다 훨씬 쉽게 알고리즘을 구현할 수 있다.
아래의 소스 코드는 Hadoop 관련 예제에 많이 등장하는 WordCount 예제다. MapReduce 보다 훨씬 간결하게 코드를 작성할 수 있다.
DataSet<String> input = env.readTextFile(inputPath); DataSet<Tuple2<String, Long>> words = input.flatMap((value, out) -> { for (String s : value.split(" ")) { out.collect(new Tuple2<String, Long>(s, 1L)); } }); words.groupBy(0).sum(1).writeAsText(outputPath);
Apache Flink는 Delta Iterate라는 특이한 연산을 지원하는데, 간단히 소개하자면 한번 반복이 진행 된 후 다음에 계산할 필요가 있는 후보들만 계속해서 반복함으로써 반복의 수를 줄여 수행 시간을 단축하는 데 도움을 준다. Delta Iterate 연산은 특히 그래프 내에서 Propagation 등을 수행하는 경우 유용하다.
Hadoop과의 호환성도 좋아서 Hadoop에서 사용하던 InputFormat, OutputFormat, Map Function, Reduce Function 등도 그대로 사용할 수 있고 YARN 클러스터 위에서 작동 할 수도 있다.
Github에 Apache Flink를 사용한 예제 구현을 만들어 코드를 올려봤다. 100줄도 안되는 코드로 분산 클러스터에서 작동하는 PageRank 알고리즘을 구현할 수 있었다.